Defining Spaces
Observation Space
The implementations of the observation spaces are in the obs_convertion folder. The base class is ObservationGenerator, which outlines methods to be implemented in an observation space. See the diagram below for the full class interdependence.
Note: ABC refers to Python's Abstract Base Classes.
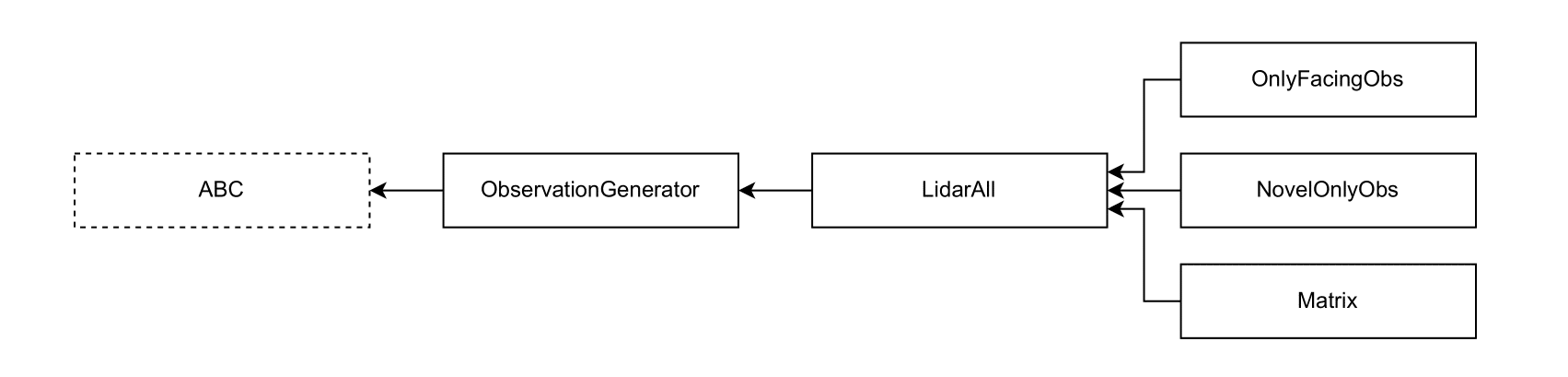
Currently Implemented Observation Spaces
All of the currently implemented observation spaces are gymnasium Box spaces:
-
LidarAll has a single Box space made from a one-dimensional vector with the item selected by the agent, the agent's inventory, and the euclidean distances to the objects that strike the LiDAR beam sent by the agent in 45 degree increments,
-
OnlyFacingObs (child of LidarAll) limits the number of LiDAR beams sent,
-
NovelOnlyObs (child of LidarAll) limits the types of objects detected,
-
Matrix (child of LidarAll) holds a dictionary with three Box spaces – one for the agent's selected item, one for the agent's inventory, and one for the agent's local view stored as a two-dimensional square image.
Adding New Observation Spaces
To integrate a new observation space:
-
declare a child of LidarAll in the obs_convertion folder and override any parts of the parent class,
-
if the structure of the new space differs from that under LidarAll:
-
add a compatible net to the net folder,
-
implement a new policy in the policy_utils.py file,
-
add a case to the train.py file so that the right policy-maker is called instead of
create_policywhen the new observation space is being used,
-
-
list the new space in the obs_convertion/__init__.py file consistent with the spaces already there,
-
include the new space under
OBS_TYPESin config.py so that the space can be chosen when training is being run from the command line.
Action Space
The agent's action space is automatically generated from the config file. Hence, all you need to do to integrate a new action is write the module representing it and reference this module in the config.
Of course, you can also modify or override the action_space method of the SingleAgentWrapper class. This class is explained in the Combining Planning & RL Agents section.
Reward Function
The reward is generated from the observation module by the SingleAgentWrapper and passed to the external RL agent.
Additional reward is generated in the reward-shaping and neurosymbolics wrappers. These are found in the envs folder and described in detail in the Combining Planning & RL Agents section.